I mumble to Claude on my couch while my family wonders who I’m talking to. I vibe code in the car while my son drives. I rent the most expensive brain I can get. This is my CHOP (Chat-Oriented Programming) setup: the infrastructure, the tools, and what I’ve learned.

- The Brain I Rent
- Tools of the Trade
- Notes from the Trenches
- The Control Panel - For This Human
- Where I Code
- Making AI Work My Way
- My Projects
- The Server Behind the Curtain
- A Typical CHOP Session
- Appendix: Origin of a Tool Nerd
- Appendix: Who I Follow
- Appendix: The Long View
- Appendix: Open Questions
The Brain I Rent
The core problem: Different models have different intelligence, and you get what you pay for. You can get a middle schooler or you can get a university student.
The Most Expensive I Can Get
Currently I’m using Claude Opus 4.5 on the $200/month plan.
On one hand you might think I’m crazy spending $2,400 a year. On the other hand, imagine having brilliant collaborators who force multiply everything you do, train you up, and basically give you a PhD in whatever you’re working on.
Why Not Codex, Gemini, etc.?
In November 2025, Gemini came out and I was like “Oh my god, I’ve got to try this, this is awesome.” Then the new Codex came out three days later and I was like “Oh my god, I’ve got to try this, this is awesome.” Then Opus 4.5 came out and I was like “Oh my god, I’ve got to try this, this is awesome.”
Then I realized: all I’m doing is spinning between tools that keep leapfrogging each other. I decided to standardize on Claude Code and assume it’ll catch up quickly if it ever falls behind.
The one gap: Claude Code can’t generate images. I use ChatGPT for that, currently manually. (Note to self: I should write a script to generate images via the API.)
When I Need Speed: Groq
Sometimes I need really low latency. For those cases I run models served off Groq. They can get down to ~100ms response times, which is pretty awesome for interactive use cases.
(A terminology nit: “Claude” and “ChatGPT” are products, not models. The actual models are Opus, Haiku, GPT-4o, Llama - with version numbers. Groq is an inference provider. Everyone, including me, uses these terms loosely.)
When Models Get Smarter
Looking at how fast things are moving, a natural question: what happens when models get smarter? For this, read Situational Awareness - it introduces the concept of “OOMs” or orders of magnitude in capability.
Given history, I imagine there will be more OOMs. But honestly, even if there aren’t, we’re at the point of electricity being invented. Thomas Edison invented it, and then how long did it take to find all the applications? A really long time. We’re still early.
Tools of the Trade
The core problem: The tools keep changing. What was state-of-the-art six months ago is now deprecated. How do you invest wisely when the ground keeps shifting?
The Past: Cursor
It’s crazy how fast AI evolves. In 2024, Cursor was the hot new thing. It was really about super-powered tab completion - you’d type a bit and it would complete intelligently. That model is already long gone.
The Present: Claude Code
Claude Code is really about autonomous agents that run in your terminal. As a terminal guy, I can speak to why this is so awesome - it fits my workflow perfectly. The agent runs commands, edits files, and iterates without me micromanaging every step.
The Future: Multi-Agent Dashboard
I was surprised when Steve Yegge mentioned this is the future - orchestrating multiple specialized agents. Surprised because I’d been accidentally building toward this. The Agent Dashboard I mentioned earlier? By the way, I didn’t build that at all. I just gave the requirements and Claude built it itself.
The 8 Stages of AI Coding
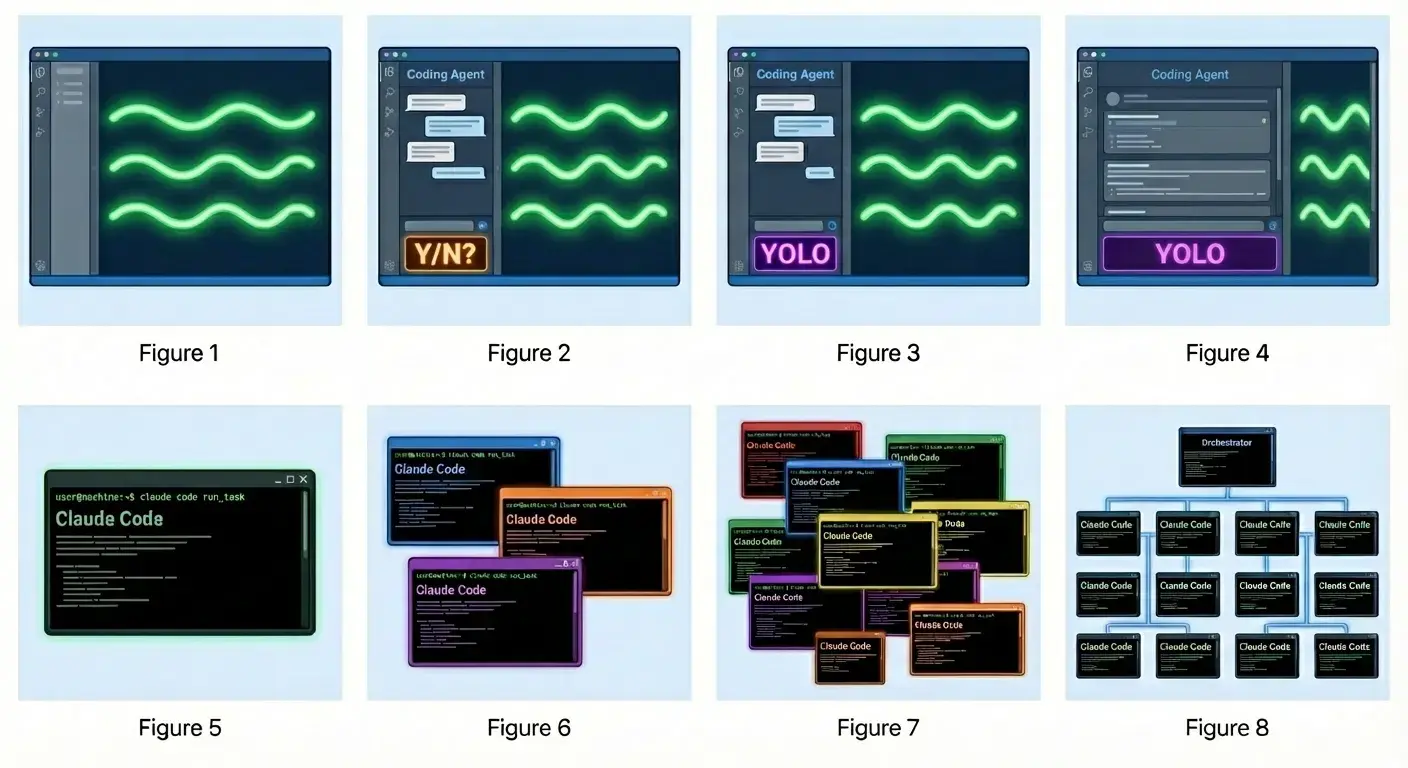
This diagram perfectly captures the evolution I’ve lived through. Let me break down what each stage actually means:
Stages 1-4: The Solo Developer Journey
-
Manual Coding - Just you and your editor. Every line typed by hand. The good old days (which weren’t always that good).
-
Approval-Based Agent (Y/N?) - AI suggests changes, but stops to ask permission for each action. This is where Cursor started - tab completion evolved into “should I run this test?”
-
YOLO Mode - The turning point. AI can execute commands, make commits, run tests without asking each time. This is what YOLO Containers enable safely.
-
Full Autonomy - AI doesn’t just execute commands - it plans multi-step workflows and handles the entire development cycle. This is where Claude Code shines today.
Stages 5-8: The Multi-Agent Era
-
Single Agent - One Claude Code session per project. Good for focused work, but limited by serial execution. This is where most people are today.
-
Parallel Agents - Multiple Claude Code instances working on different features simultaneously. You become a coordinator, switching between agents. This is when you discover the pain of merge conflicts and context switching.
-
Specialized Tools - Different agents have different capabilities. One handles tests, another docs, another deployment. You’re orchestrating specialists, not generalists. The optimal number of agents becomes critical.
-
Orchestrated System - This is the vision: a central dashboard managing dozens of specialized agents. The Agent Dashboard is an early step toward this. You’re no longer coordinating individual agents - you’re managing the system that coordinates them.
Where I Am Today: Somewhere between stages 6 and 7. Running 2-3 parallel agents on different features, learning how to avoid merge hell, figuring out when to use specialized vs. generalist agents. Stage 8 is the dream, but the tooling isn’t quite there yet.
Notes from the Trenches
What Works Well - REVIEW THIS WEEKLY!
Note to self: Review this section regularly. These principles are easy to forget when you’re heads-down in a session.
- Rent the most expensive brain you can: Spend tokens liberally. Don’t be cheap with AI usage - the $200/month is nothing compared to the force multiplication you get
- Maximize time between interventions: Like Tesla’s self-driving metrics, the goal is reducing how often you need to take over. Every friction point kills flow
- Don’t be the intern doing grudge work: If AI writes code and you manually test it, you’ve got the roles backwards. Make AI the tester too - be the architect, not the QA intern
- Tests as specification: The clearer the tests, the less I need to intervene
- Always be able to rewind: YOLO containers and git workflows mean you can experiment fearlessly. If something breaks, spin up a fresh container in seconds
- Conventions compound: Time spent on CLAUDE.md pays off across every session
- Isolation is freedom: YOLO containers let Claude run autonomously without risk to my real environment
- “Don’t glaze me” changes everything: Claude is far more useful when it pushes back on bad ideas
- Rot repair is nearly free: Reviving a stale project used to mean a weekend of toolchain archaeology (Software Rot); now an agent grinds through the upgrades for me
What I’m Still Figuring Out
- How to handle merges: When multiple agents touch related code, merging gets messy fast.
The optimal number of agents deserves its own callout. On one hand, the number you can run in parallel seems to be the limiting factor for throughput. On the other hand - man, it’s easy to get confused. Sending the wrong commands to the wrong agents. Forgetting what each one is doing. Brutal merge conflicts when they touch the same files. It’s quite the challenge, and I’m nowhere close to having it figured out.
Rethinking conventional coding wisdom:
- DRY vs. self-contained: Should conventions be shared libraries, or should every repo implement its own? When execution is cheap, maybe copy-paste isn’t so bad.
- Planning vs. iterating: When you can execute so quickly, is planning even worth it? Or are you better off just iterating fast?
- Tests first vs. tests after: If AI can generate tests instantly, does TDD still matter? Or is “describe what you want, let AI figure out the tests” the new workflow?
The Control Panel - For This Human
The core problem: agents are slow, not fast. The mitigation? Run several in parallel. But humans aren’t designed for parallel orchestration. You need a cockpit — voice input, physical buttons, a dashboard, and instant session switching — to keep track of it all without losing your mind.
I wrote up the full cockpit setup separately:
Where I Code
Not a problem - an opportunity. When things change, previous constraints change too. Voice coding + cloud containers = newfound freedom. I’m no longer tethered to a desk with a keyboard. I’m still figuring out how to use this freedom.
The Couch
I really like coding on the couch because I feel like I’m with my family even though I’m there mumbling. There’s a bit of a lie here - I kind of don’t see my family and they’re very confused about who I’m talking to.
Humorous side note: after a coding binge where I did 60 hours of vibing two weeks in a row, when I stopped my family asked “Are you okay? You’re not just mumbling to yourself anymore.”
The Coffee Shop
Unfortunately I can’t use voice here, but I really enjoy being at a coffee shop - seeing the people, the ambient noise, all that jazz. There’s something about the energy of a public space that keeps me focused.
The Desktop Setup
Using a big monitor is awesome - all that real estate. I’ve also experimented with using multiple monitors to help me keep track of different things: agents running in one screen, code in another, docs in a third.
The Walking Treadmill
Just today, as I was writing this post, I realized: “Hey, I could do this walking since I’m using voice.” So parts of this post were spoken while walking on my under-desk treadmill. Kind of cool.
The Car
Yes, I can vibe code in the car too. My 16-year-old son is learning to drive and drove us back from a 10-hour drive from Ashland, Oregon. I spent the entire time vibecoding. That probably contributed to my shoulder impingement.
Ergonomics

The danger of all this freedom. Be careful about ergonomics, especially if you’re an older coder. Coding on couches, in cars, and in awkward positions adds up. Your body will eventually present the bill.
Making AI Work My Way
For nerds: This whole strategy fights against the Bitter Lesson. Rich Sutton argued that simple methods + more compute beats hand-crafted human knowledge. Building elaborate CLAUDE.md files and conventions is exactly that - encoding human knowledge instead of letting models get smarter. The irony isn’t lost on me.
The core problem: Every session, the AI starts fresh. It doesn’t remember your preferences, your project structure, or what you’ve already discussed. Conventions are how you encode context that persists.
The chop-conventions Repo
I maintain a shared conventions repo at idvorkin/chop-conventions that I link into projects. This gives me:
- Consistent rules across all my repos
- Easy updates - change once, propagate everywhere
- Version controlled evolution of my AI instructions
The first thing I tell Claude to do in any project: clone this repo and read the starting guide.
CLAUDE.md Structure
My CLAUDE.md files follow a pattern: foundational rules (honesty, call out bad ideas), guardrails (no pushing to main, no removing tests), relationship framing (we’re colleagues, push back when I’m wrong), and project-specific guidance.
The theory: tell Claude how to think, not just what to do. Whether “don’t glaze me” actually shapes behavior across sessions? I genuinely don’t know.
Here’s the thing: every time models get smarter and tools get better, my CLAUDE.md becomes partially obsolete. Especially the alchemy - yelling at the model, begging it not to do a bad job, elaborate prompting tricks. That stuff has a short half-life. But some things stay useful: custom commands to run, project-specific context, where to find things. The challenge is knowing which is which.
MCP Servers and Skills
At the end of the day, I don’t use much of this. Often I’ll install something, try it out, and it just gets left running in the background. GitHub MCP for issue/PR management, maybe some doc fetching. That’s about it.
This stuff changes so fast, and with models getting smarter (see the Bitter Lesson discussion in Making AI Work My Way), we’ll just get to it later. Two or three max.
What does matter: Little CLI programs for my agents to run. Same principle as with humans - instead of giving someone detailed directions, give them a tool that just works perfectly to solve the problem.
For example, I have running-servers that checks if a Jekyll server is already running for a directory, so agents don’t try to recreate them. Instead of prompting the agent through “check ps, grep for jekyll, parse the port numbers, compare to current directory…” - just give them a tool that answers “is there a server for this directory?” These custom tools that extend what agents can do - those are worth building.
My Projects
Command Line and PWAs
Most of my tools are either command line or PWAs. Command line - obviously, when I’m on the command line, which is often. For everything else, PWAs: local-first, run everywhere, no app store hassle. They’re remarkably flexible.
CHOP has made it so much easier to spin up new ideas and actually finish them.
Testing and Evals
This might be the most important thing. In the CHOP world, knowing how to verify that AI output is correct matters more than knowing how to produce it. It’s all about evals - can you define what “good” looks like and measure whether you’re there?
Once the eval is sharp, the search loop runs itself: eval-driven hill climbing — the agent proposes variants, the eval scores them, the winner becomes the next baseline. You write the fitness function; the agent does the climbing.
The Server Behind the Curtain
The metric that matters most in CHOP is time between interventions. Like Tesla’s self-driving, the goal is reducing how often you need to take over. Every friction point - waiting for a slow laptop, losing context when you switch machines, being scared to let the AI run autonomously - increases interventions and kills your flow.
My hosting environment is designed to minimize these interruptions.
Why Not Cloud Environments?
Why not just use Claude Cloud, Jules, Codespaces, or other hosted environments? They’re limited in their setup - you can’t customize the tooling, install arbitrary dependencies, or configure things exactly how you want. And honestly, it’s easy enough to set up your own. The initial investment pays off quickly when you’re not fighting constraints.
Hardware Setup
Why it matters: I can start a CHOP session at home, close my laptop, commute, and pick up from a different device. The work lives in the container, not on any particular machine. Zero intervention required for location changes.
A desktop machine runs multiple Docker containers. I mosh in from laptops, tablets, wherever. (Mosh is self-reconnecting SSH - survives laptop sleep, network switches, everything.)
Container Setup
Why it matters: Agents will wipe your machine. Give them YOLO mode on your laptop and eventually one will rm -rf something important or force-push to main. Containers provide isolation - if Claude breaks something, the blast radius is one disposable container, not your life’s work.
I run AI agents in isolated Docker containers - cattle, not pets. Full details in YOLO Containers, but the key points:
- Each container gets YOLO mode (agents run without asking permission for anything)
- Separate GitHub identity (
idvorkin-ai-tools) - can only create PRs, not push to main - Named volumes for persistence across restarts
- Multiple containers for parallel CHOP sessions on different features/repos
- CPU guard: an OrbStack VM core cap plus a small userspace watchdog that attaches
cpulimitto any runaway process — one feral agent can’t starve the other five when half a dozen are running in parallel
Network Setup
Why it matters: No port forwarding, no VPN configuration, no “works on my machine.” I can share a preview link with anyone on my tailnet, or pull up my work on my phone to check something. Location-independent access to everything.
Every container joins my Tailscale mesh network and gets a stable hostname:
- Container
c-5001becomesc-5001.squeaker-teeth.ts.net - Servers bind to
0.0.0.0so they’re network-accessible - Same URLs work from home, coffee shop, or traveling
A Typical CHOP Session
TODO: Still figuring this out. The workflow changes frequently as tools evolve.
Appendix: Origin of a Tool Nerd
The Enabling Environment
This philosophy is why I invest in CHOP infrastructure. Every minute spent on container setup, conventions, and tooling is friction removed from future work. The enabling environment isn’t about productivity for its own sake - it’s about creating the conditions where good work can happen naturally.
CHOP is the latest chapter in this story: building systems that let me focus on the interesting problems while automating the tedious ones.
My Relationship with Tools
I’ve always been a tool nerd. VIM since forever. Command line over GUI. Custom scripts for everything. The joy isn’t just efficiency - it’s the craft of building your own workshop.
CHOP fits this pattern: I’m not just using AI, I’m building an AI-augmented development environment. The containers, the conventions, the workflows - they’re all tools I’m crafting for a new kind of work.
Is This a Waste?
Every month your setup is stale. New models drop. New tools appear. Best practices from six months ago are now anti-patterns. Is it even worth trying to keep up?
I spent years mastering VIM. Was that a waste? I built elaborate tmux workflows. Will that matter in two years? I’m investing in container infrastructure and conventions. Is this the buggy whip factory of 2025?
My answer: it depends on what you’re actually learning.
- Learning specific keystrokes? Maybe a waste.
- Learning to reduce friction and build enabling environments? Transferable forever.
- Learning a specific tool’s quirks? Probably temporary.
- Learning how to delegate effectively to agents? That’s the new core skill.
The meta-skill is knowing which investments compound and which depreciate. Right now, I’m betting that orchestration skills (conventions, delegation, verification) will outlast implementation skills (specific languages, specific tools).
Appendix: Who I Follow
Simon Willison
I read Simon Willison religiously. So much content, constantly experimenting, always sharing what he learns. If you’re only going to follow one person on AI-assisted development, make it him.
Steve Yegge
Steve Yegge is my hero. Super fun to read, deeply experienced, and unafraid to have strong opinions. His takes on where AI coding is headed are worth paying attention to.
Huge mixed bag. Sometimes there’s something genuinely good. Usually it’s people selling stuff. I keep a list but approach with skepticism.
Appendix: The Long View
What Management Taught Me About AI
Good delegation to humans requires clear expectations, appropriate context, and defined success criteria. Same with AI.
When delegation fails, it’s usually because:
- The task wasn’t well-specified (AI hallucinates requirements)
- Success criteria were unclear (AI optimizes for the wrong thing)
- I didn’t give enough context (AI makes reasonable but wrong assumptions)
The conventions repo and CLAUDE.md are essentially delegation infrastructure - encoding all the context an AI needs to work autonomously.
The Evolution of Junior Developers
You don’t need to know the “how” nearly as much anymore. The key skill becomes spec/verify - which is closer to PM than traditional engineering.
And what do PMs do? Two things: understand the business, and understand people - helping people feel good about what’s happening. Those skills don’t go away. If anything, they become more important when the “how” is increasingly handled by AI.
We have junior PMs. Maybe that’s the new on-ramp.
Revenge of the SDET
Back when I started in programming, we had SDETs - Software Development Engineers in Test. They were software engineers who focused more on testing than writing the actual code. These folks were kind of looked down upon, and the role eventually disappeared at most companies.
But now in the CHOP world? Testing is actually the most important thing. It’s all about the evals. The person who can specify what “correct” looks like, write the tests that verify it, and evaluate whether the AI’s output meets the bar - that’s the bottleneck skill now.
The SDETs were ahead of their time.
Hyper-Personalized Software
With coding so easy, might as well make a tool just for your use case. No need to find an app that’s 80% right - build exactly what you want in an afternoon.
I think there’s a pendulum here:
- 90s: Every company needed their own IT department
- 2000s: SaaS - rent the same software as everyone else
- 2030s: Single dev does all the required tooling, personalized to their exact needs
See more in my hyper-personalization post. Examples from my own life: handwriting journal workflow, mortality software, all my pet projects.
The Joy Question
Does CHOP kill the joy of coding? See the deeper exploration in Will CHOP Kill the Joy of Coding?.
My take: the joy shifts, it doesn’t disappear. Less joy in typing code, more joy in:
- Designing systems at a higher level
- Crafting the perfect specification
- Building the enabling environment itself
- Solving problems I couldn’t tackle alone
It’s like the transition from assembly to high-level languages. Some people mourned losing the craft of register allocation. Most found new joys in the problems they could now solve.
The Flow Question
Someone asked me: “Can you still get flow when you’re chopping? You’re not even writing the code.” They assumed no — that flow lives in the typing.
I’m in flow constantly. It comes from orchestrating — juggling two or three agents at different points in their loops, nudging one, reviewing another, letting the third cook. That rhythm is its own zone, which is exactly why I built the cockpit. And it comes from mastery — I’m nowhere near done learning how to operate these things (see /ai-operator), and challenge-meeting-skill is where flow has always lived.
That’s where the joy of chopping comes from for me. Not mourning the typing — being in the zone while orchestrating a team.
What I’m Betting On
- Practice and self-improvement always win: The tools change, but learning new skills is the constant. You’re going to suck until you die - that’s just how mastery works.
- Conventions become critical: As AI gets smarter, the bottleneck shifts to specification quality. CLAUDE.md-style files will matter more, not less.
- Verification beats implementation: Knowing what to build and how to verify it matters more than how to build it.
- Multi-agent coordination will improve: Today’s pain of running parallel agents is a tooling problem, not a fundamental limit.
- The enabling environment philosophy applies more than ever: The winners will be those who invest in reducing friction.
Appendix: Open Questions
What happens when execution is no longer the bottleneck?
Right now, we’re still limited by how fast we can build things. But that’s changing fast. What becomes the constraint then?
How do organizations handle 200x more projects? Imagine a company like Meta that used to run N projects because engineering capacity was the limit. Now they can run 200N projects. How do they even assess them all? How do they A/B test that many variants? It’s going to be a crazy world.
Reviews become more expensive than creation. LLVM hit this with PRs - they had to create a whole AI tool policy because reviewing AI-generated contributions takes more human time than the AI spent creating them. TL;DR: You’re responsible for anything your AI creates. If you can’t answer questions about what the AI did, your PR fails. But this applies to everything - not just code.
What happens post-singularity?
First, what’s a singularity? It’s when AI can generate the majority of economic value with a very small group of people who have a ton of leverage.
At that point, two problems:
- How do people eat? There are solutions - easier said than done - like UBI.
- How do people have purpose? This one is even harder. I feel it in my bones. But you know what? Humans have always figured it out, and I’m sure they’ll do it again.
Is sloppy process okay if agents can clean up the mess?
Beads constantly gets into broken states - leftover file leases, corrupted issue data, stale git references. Traditional software engineering says: prevent these states, make workflows deterministic, fail fast. But here’s the thing: agents just… fix it. They see the mess, figure out what went wrong, and recover.
Steve Yegge describes using MCP Agent Mail for multi-agent coordination: “You just give them a task and tell them to sort it out amongst themselves. There’s no ego, so they quickly decide on a leader and split things up… Although it seems crazy to work that way, the agents just figure it out—they’re quite resilient.” See his Beads Best Practices post.
This raises uncomfortable questions: If agents can recover from any workflow mess, do we still need disciplined processes? We’ve spent decades building guardrails to prevent non-deterministic states because humans can’t handle the chaos. But agents can. Maybe the discipline shifts from how you work to what you produce. Maybe it’s fine if your agents are sloppy, leave garbage lying around, and get into weird states - as long as the output is correct. The craftsmanship moves from the process to the artifact. I don’t know what to do with this yet.
(By the way, this is how I use voice. My voice input ends up being garbage - half-formed thoughts, wrong words, trailing off mid-sentence - but agents figure out what I meant and respond to my intent, not my mangled transcription. Even the input can be sloppy now.)